데이터베이스에서 탐색 속도를 빠르게 하기 위해 사용하는 인덱스에 대해 알아보자
인덱스 (index) 란?
데이터베이스 인덱스는 추가적인 쓰기 작업과 저장 공간을 활용하여 테이블의 검색 성능(속도)을 향상시키기 위해 사용되는 구조로, 특정 칼럼에 대한 정렬된 데이터를 유지하여 빠른 탐색을 가능하게 한다.
하지만 인덱스를 관리하는데 추가적인 비용이 발생하며, 데이터 변경 작업 시 성능 저하가 발생할 수 있다.

개념
- 데이터베이스에서 칼럼(속성)을 기반으로 빠른 검색을 지원하기 위한 자료구조
- 특정 칼럼 값 기반으로 테이블 행에 대한 물리적인 위치를 찾아 매핑
- 테이블에 대한 보조 구조로써 생성되며, 원본 데이터와 별도로 관리
- 특정 칼럼에 인덱스 생성 시 해당 칼럼의 데이터를 정렬 후 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장
- 칼럼 값, 물리적 주소를 (key, value) 한 쌍으로 저장
장점
- 검색 성능 향상
- 테이블 전체를 검색하는 Full Table Scan 없이 원하는 데이터를 빠르게 조회할 수 있다.
- B-Tree 인덱스의 경우 로그 시간 내에 탐색이 가능하여 성능이 개선된다.
- 시스템 부하 감소
- 검색 속도가 향상되므로 쿼리 실행 시간이 단축되고, 그에 따라 CPU 및 I/O 부하가 줄어든다.
- 정렬된 데이터 유지
- 인덱스는 자동으로 데이터를 정렬된 형태로 유지한다.
- order by, min( ), max( ) 같은 연산을 빠르게 수행할 수 있다.
- 단점
- 인덱스 관리를 위한 오버헤드가 발생 (인덱스 관리 비용 증가)
- 원하는 값을 빠르게 탐색하기 위해 항상 정렬된 상태로 유지해야 한다.
- 삽입 (insert) : 새로운 데이터가 추가될 때마다 인덱스도 업데이트 되어야 한다.
- 삭제 (delete) : 삭제된 데이터의 인덱스는 즉시 제거되지 않고, '사용하지 않음' 상태로 남아 관리 부담이 증가한다.
- 수정 (update) : 기존 데이터를 변경하면 새로운 인덱스를 생성 또는 재작성해야 하므로 성능 저하가 발생할 수 있다.
- 원하는 값을 빠르게 탐색하기 위해 항상 정렬된 상태로 유지해야 한다.
- 추가적인 저장 공간 필요
- 인덱스를 저장하기 위해 테이블 크기의 약 10% 정도의 추가적인 저장 공간이 필요하다.
- 데이터 변경이 많을 경우, 불필요한 인덱스가 쌓여 디스크 공간 낭비가 발생할 수 있다.
- 일부 경우에는 Full Table Scan이 더 효율적
- 데이터가 극도로 적은 경우(ex. 1개 또는 몇 개의 행만 있는 테이블)에는 인덱스 검색보다 풀스캔(Full Table Scan)이 더 빠를 수도 있다.
- 검색 대상이 테이블의 대부분을 차지하는 경우(ex. 90% 이상의 데이터를 조회하는 경우)에도 인덱스가 큰 이점을 제공하지 못할 수도 있다.
- 한 페이지를 동시에 수정할 수 있는 병행성이 줄어든다.
인덱스를 사용하면 병행성이 줄어드는 이유
인덱스를 사용하면 특정 데이터를 더 빠르게 조회할 수 있지만, 동시에 여러 트랜잭션이 같은 페이지를 수정할 때 병행성이 낮아지는 문제가 발생할 수 있습니다.
이유를 살펴보겠습니다.
1. 인덱스와 병행성의 관계
(1) 인덱스 없이 데이터를 수정하는 경우
- 테이블에서 특정 데이터를 수정할 때, 테이블 전체를 스캔(Full Table Scan) 하면서 해당 데이터를 찾아 변경합니다.
- 일반적으로 한 트랜잭션이 수정하는 데이터가 랜덤하게 분산되어 있어 같은 페이지(Page)에서 충돌이 적습니다.
- 따라서, 서로 다른 트랜잭션이 동시에 수정할 확률이 낮아 병행성이 높습니다.
(2) 인덱스를 사용하여 데이터를 수정하는 경우
- 인덱스를 사용하면 특정 데이터를 빠르게 찾을 수 있지만, 동일한 인덱스 키 값을 가진 레코드들이 동일한 페이지에 저장될 가능성이 높아집니다.
- 즉, 같은 인덱스 범위에 속하는 데이터가 물리적으로 같은 페이지(Page)에 위치하게 됩니다.
- 따라서, 여러 트랜잭션이 같은 인덱스 키 값을 가지는 데이터를 수정하려 할 경우 동시에 같은 페이지를 수정하려는 충돌이 발생할 확률이 높아집니다.
2. 인덱스 사용으로 병행성이 줄어드는 원인
(1) 페이지 레벨 락(Page-Level Lock)
- 인덱스가 적용된 테이블에서 데이터를 수정할 때, 한 페이지에 있는 여러 행이 같은 인덱스 값을 가지면 해당 페이지 전체에 락이 걸릴 수 있습니다.
- 한 트랜잭션이 페이지를 수정하는 동안, 다른 트랜잭션은 해당 페이지에 접근할 수 없기 때문에 동시 수정이 어려워집니다.
- 결과적으로, 병행성이 낮아지고 트랜잭션 처리 속도가 느려질 수 있습니다.
(2) 인덱스 재조정(Index Rebalancing)
- B-Tree 인덱스를 사용할 경우, 데이터가 삽입되거나 삭제될 때 인덱스의 균형을 유지하기 위해 노드가 분할(Split) 또는 병합(Merge)될 수 있습니다.
- 이 과정에서 기존의 인덱스 구조가 변경되면서 여러 트랜잭션이 동시에 수정하기 어려워질 수 있습니다.
- 특히, 자주 변경되는 열(예: 순차적인 ID, 날짜 등)에 인덱스가 걸려 있다면, 특정 페이지가 집중적으로 수정되면서 충돌이 자주 발생할 수 있습니다.
(3) 갱신 시 추가적인 인덱스 수정 비용
- 데이터를 수정하면, 기본 테이블의 데이터뿐만 아니라 해당 데이터를 참조하는 인덱스도 함께 변경해야 합니다.
- 만약 하나의 테이블에 여러 개의 인덱스가 존재하면, 한 번의 수정 작업이 여러 개의 인덱스 페이지를 동시에 수정해야 하는 문제가 발생합니다.
- 특정 페이지가 여러 트랜잭션에 의해 동시에 수정될 경우, 경쟁(Conflict)으로 인해 병행 처리가 어려워지고, 전체 성능이 저하될 수 있습니다.
3. 예제: 인덱스가 병행성에 미치는 영향
(1) 인덱스가 없는 경우 (Full Table Scan)
UPDATE Orders SET status = 'Completed' WHERE order_id = 1001;
- order_id 열에 인덱스가 없는 경우, 테이블을 처음부터 끝까지 스캔하면서 해당 데이터를 찾아 변경합니다.
- 데이터가 랜덤한 위치에 저장되어 있어, 동시에 여러 트랜잭션이 다른 페이지의 데이터를 수정할 가능성이 높습니다.
- 따라서 병행성이 높아집니다.
(2) 인덱스가 있는 경우 (Index Range Scan)
UPDATE Orders SET status = 'Completed' WHERE status = 'Pending';
- status 열에 인덱스가 존재하는 경우, 인덱스를 사용해 'Pending' 상태인 모든 주문을 빠르게 찾을 수 있습니다.
- 하지만, 같은 상태 값(Pending)을 가지는 주문들이 동일한 페이지에 저장될 가능성이 높아집니다.
- 이로 인해 여러 트랜잭션이 동시에 'Pending' 상태인 주문을 수정하려 할 경우 같은 페이지를 수정하려는 충돌이 발생하게 됩니다.
- 즉, 병행성이 낮아질 수 있습니다.
4. 병행성을 높이는 방법
인덱스로 인해 병행성이 줄어드는 문제를 해결하려면 다음과 같은 방법을 고려할 수 있습니다.
✅ (1) 적절한 인덱스 설계
- 자주 변경되는 열에 대한 인덱스를 최소화해야 합니다.
- 특히, 한정된 범위의 값(예: status='Pending')을 가지는 컬럼에 인덱스를 설정할 경우 특정 페이지에 데이터가 집중될 수 있습니다.
- 이러한 경우, 클러스터형 인덱스(Clustered Index)나 해시 인덱스(Hash Index) 등을 활용하여 데이터를 분산 저장할 수 있습니다.
✅ (2) 데이터 수정 시 인덱스를 활용하는 방식 개선
- 데이터 수정 작업이 인덱스를 사용하여 특정 페이지에 집중되지 않도록 랜덤한 값이 포함된 키를 활용하여 트랜잭션을 분산시킬 수 있습니다.
- 예를 들어, ORDER BY RAND() 같은 기법을 사용하여 업데이트 순서를 무작위로 변경하면 페이지 충돌을 줄일 수 있습니다.
✅ (3) 락 전략 조정
- 페이지 락(Page-Level Lock) 대신 행 단위 락(Row-Level Lock) 을 적용하여 병행성을 높일 수 있습니다.
- MySQL의 InnoDB 스토리지 엔진은 기본적으로 행 단위 락(Row-Level Lock)을 사용하지만, 특정 조건에서 페이지 락이 발생할 수 있으므로 주의해야 합니다.
✅ (4) 파티셔닝(Partitioning) 활용
- 테이블을 여러 개의 파티션으로 나누어 트랜잭션이 서로 다른 파티션에서 실행되도록 유도하면 병행성을 높일 수 있습니다.
- 예를 들어, status 값을 기준으로 다른 파티션에 데이터를 저장하면 특정 페이지에 트랜잭션이 몰리는 현상을 방지할 수 있습니다.
5. 결론
✔ 인덱스는 데이터를 빠르게 조회하는 데 도움을 주지만, 동일한 인덱스 키 값을 가진 데이터가 한 페이지에 집중되면서 병행성이 낮아질 수 있습니다.
✔ 특정 페이지가 여러 트랜잭션에 의해 동시에 수정되면 락 충돌이 발생하여 성능이 저하될 수 있습니다.
✔ 이를 해결하기 위해, 인덱스 설계를 신중하게 하고, 락 전략을 최적화하며, 파티셔닝을 활용하는 등의 방법을 고려해야 합니다. 🚀
Index 를 사용하면 좋은 경우
- Where 절에서 자주 사용되는 Column
- 외래키가 사용되는 Column
- Join에 자주 사용되는 Column
Index 사용을 피해야 하는 경우
- 데이터 중복도가 높은 Column
- DML이 자주 일어나는 Column
DML이 일어났을 때의 상황
INSERT
기존 Block에 여유가 없을 때, 새로운 Data가 입력된다.
→ 새로운 Block을 할당 받은 후, Key를 옮기는 작업을 수행한다.
→ Index split 작업 동안, 해당 Block의 Key 값에 대해서 DML이 블로킹 된다. (대기 이벤트 발생)
→ 이때 Block의 논리적인 순서와 물리적인 순서가 달라질 수 있다. (인덱스 조각화)
DELETE
<Table과 Index 상황 비교>
Table에서 data가 delete 되는 경우 : Data가 지워지고, 다른 Data가 그 공간을 사용 가능하다.
Index에서 Data가 delete 되는 경우 : Data가 지워지지 않고, 사용 안 됨 표시만 해둔다.
→ Table의 Data 수와 Index의 Data 수가 다를 수 있음
UPDATE
Table에서 update가 발생하면 → Index는 Update 할 수 없다.
Index에서는 Delete가 발생한 후, 새로운 작업의 Insert 작업 / 2배의 작업이 소요되어 힘들다.
인덱스 자료구조
인덱스를 구현하는 대표적인 자료구조로는 해시 테이블 (Hash Table)과 B+Tree가 있다.
각 자료구조는 특성이 다르며 특정한 검색 연산에 따라 적절한 방식이 선택된다.
1. 해시 테이블 (Hash Table)
key와 value를 한 쌍으로 데이터를 저장하는 자료구조
- (key, value) 구조로 데이터를 저장하는 자료구조
- key 값을 입력하면 해시 함수(Hash Function)를 이용해 대응되는 value 값을 빠르게 찾을 수 있다.
- 평균적으로 O(1)의 탐색 속도를 가진다. (단, 해시 충돌 발생 시 성능이 저하될 수 있다.)
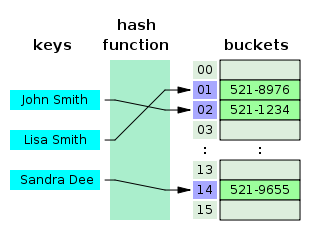
해시 테이블 기반 인덱스의 한계
해시 테이블은 O(1)이라는 빠른 검색 속도를 제공하지만, 데이터베이스의 인덱스로 잘 사용하지 않는다.
- 해시 테이블은 등호(=) 연산에 최적화 but 데이터 베이스에서는 부등호 연산이 자주 사용됨
범위 검색 불가능 → 해시 테이블은 순서가 없는 구조 : '<' 또는 '>'와 같은 부등호 연산이 비효율적이다. - 정렬 기능이 없다. → order by, min( ), max( ) 와 같은 연산을 빠르게 처리할 수 없다.
- 부분 검색이 어렵다. → 문자열 일부 검색 (ex. like '%apple%') 같은 작업이 어렵다.
따라서 대부분의 데이터베이스에서는 해시 테이블 대신 B+ Tree를 인덱스로 사용한다.
2. B+Tree
B+Tree는 기존 B-Tree를 개선한 자료구조로, 데이터베이스 인덱스에서 가장 널리 사용되는 구조이다.
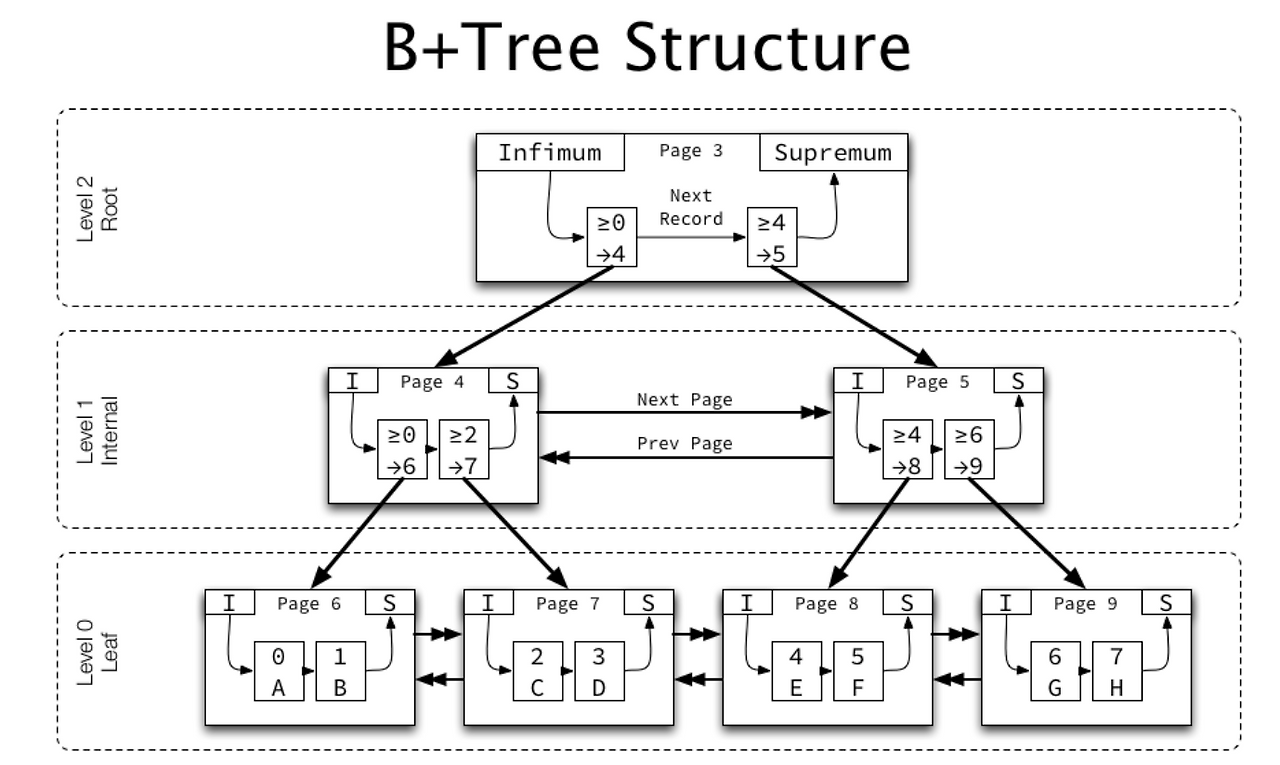
장점
- 모든 데이터는 리프(leaf) 노드에 저장됨
- 리프 노드끼리 Linked List 형태로 연결 → 순차 탐색(부등호 연산)이 매우 효율적
- 중간 노드는 검색을 위한 key 값과 자식 포인터만 저장 : 포인터의 역할만 수행
- 중간 노드에서 key를 올바르게 찾아가기 위해 key가 중복될 수 있다.
작동 방식
[30 | 60] ← Root 노드 (중간 노드)
/ | \
[10|20] [40|50] [70|80|90] ← 리프 노드 (데이터 저장)- 30과 60은 검색을 위한 key 값
- 데이터는 리프 노드인 [10, 20], [40, 50], [70, 80, 90]에 저장
- 리프 노드끼리 Linked List로 연결되어 있어, 범위 검색시 빠르게 이동 가능
인덱스의 존재 여부와 order by / group by 연산의 동작 과정
데이터베이스에서 order by와 group by 연산은 정렬과 그룹화를 수행하는 중요한 기능이다.
그러나 인덱스(index)의 존재 여부에 따라 성능 차이가 크게 발생할 수 있다.
다음은 인덱스가 있을 때와 없을 때의 각 동작 방식과 차이점을 설명하려고 한다.
1. order by 연산과 인덱스
order by
order by는 결과 데이터를 특정 열을 기준으로 정렬할 때 사용 이때 → 정렬할 열의 값을 비교하면서 데이터를 재배열하는 과정 필요
인덱스가 없을 경우 (order by 대상 열에 인덱스가 없는 경우)
- 전체 테이블을 읽고(Full Scan Table) 정렬을 수행해야 한다.
- 데이터가 많을 수록 정렬 비용(시간, 메모리 사용량)이 급격히 증가한다.
- 비효율적인 정렬 방식 → 성능 저하 발생
example
| id | name | age |
| 3 | 철수 | 25 |
| 1 | 영희 | 22 |
| 2 | 민수 | 30 |
🔻 ORDER BY age ASC; 수행 시
- 전체 데이터를 읽고 (age 기준 비교)
- 정렬 알고리즘 수행
- 새로운 순서로 결과 출력
단점: 추가적인 정렬 작업이 필요하여 느림
대량 데이터일수록 심각한 성능 저하 발생
인덱스가 있을 경우 (ORDER BY 대상 열에 인덱스가 존재하는 경우)
- 데이터베이스는 이미 정렬된 인덱스 데이터를 이용하여 빠르게 결과를 반환한다.
- 추가적인 정렬 작업 없이 인덱스를 순차적으로 읽으면 되므로 성능 향상된다.
example : 만약 age 열에 인덱스가 설정되어 있다면:
CREATE INDEX idx_users_age ON users(age);
🔻 ORDER BY age ASC; 수행 시
- 인덱스를 사용하여 이미 정렬된 데이터 접근
- 정렬 작업 없이 결과 반환
장점: 빠른 정렬, 성능 향상
2. GROUP BY 연산과 인덱스
GROUP BY
GROUP BY는 특정 열을 기준으로 데이터를 그룹화할 때 사용한다.
일반적으로 SUM(), COUNT(), AVG() 같은 집계 함수와 함께 사용되어 그룹별 데이터를 요약할 때 유용하다.
example : age별로 사용자 수를 구하기
SELECT age, COUNT(*) FROM users GROUP BY age;
인덱스가 없을 경우 (GROUP BY 대상 열에 인덱스가 없는 경우)
- 데이터베이스는 전체 테이블을 스캔하며 그룹화해야 한다.
- 비효율적인 연산 → 데이터가 많을수록 성능 저하
example
| id | name | age |
| 1 | 철수 | 25 |
| 2 | 영희 | 30 |
| 3 | 민수 | 25 |
| 4 | 지수 | 30 |
| 5 | 민지 | 25 |
🔻 GROUP BY age; 수행 시
- 전체 데이터를 읽음
- age 값을 기준으로 그룹화
- 각 그룹에 대해 COUNT 수행
단점: 모든 데이터를 한 번 읽고, 추가적인 그룹화 과정 필요 → 속도 저하
인덱스가 있을 경우 (GROUP BY 대상 열에 인덱스가 존재하는 경우)
- 인덱스를 사용하면 동일한 값들이 연속적으로 저장되어 있어 그룹화 작업이 빨라짐
- 인덱스는 이미 정렬된 구조이므로, 그룹별 데이터 탐색 속도 향상
example : 만약 age 열에 인덱스가 설정되어 있다면:
CREATE INDEX idx_users_age ON users(age);
🔻 GROUP BY age; 수행 시
- 인덱스를 사용하여 이미 정렬된 데이터 접근
- 같은 값이 연속되어 있으므로 빠르게 그룹화 가능
장점: 빠른 그룹화, 성능 향상
3. ORDER BY / GROUP BY 성능 비교 (인덱스 유무 차이)
| 연산 인덱스 없음 | 연산 인덱스 있음 | |
| ORDER BY | 전체 테이블 읽고 정렬 수행 (느림) | 인덱스 순차 읽기 (빠름) |
| GROUP BY | 전체 테이블 읽고 그룹화 (느림) | 인덱스 연속 저장 활용 (빠름) |
기본키와 인덱스
- 기본키 : 데이터베이스 테이블에서 각 행을 고유하게 식별하기 위해 사용되는 열 또는 열의 집합
- 외래키 : 관계형 데이터베이스에서 한 테이블의 열이 다른 테이블의 기본키를 참조하는 경우 사용되는 열
참조 무결성을 유지하고 테이블 간의 관계 설정 시 사용
- 참조 무결성 : 한 테이블의 데이터가 다른 테이블을 참조할 때 참조된 데이터가 반드시 존재해야 함을 의미 - 인덱스 : 데이터베이스에서 데이터에 대한 검색 및 정렬을 향상시키기 위해 생성되는 데이터 구조
- 기본키와 인덱스
- 기본키는 인덱스가 될 수 있지만, 기본키가 반드시 인덱스인 것은 아니다.
- 하지만 일반적으로 기본키 열에는 인덱스가 자동으로 생성되어 기본키의 고유성과 검색 성능을 보장하는데 사용된다.
- 외래키와 인덱스
- 외래키 관계를 사용해 테이블 간의 JOIN 작업을 수행하거나 외래키 열을 검색하는 경우 인덱스를 활용해 검색 성능을 향상시킬 수 있다.
- 따라서 외래키 열에는 인덱스를 생성하는 것이 좋으며, 일반적인 관례로 외래키 열에 인덱스를 생성한다.
reference
https://github.com/jmxx219/CS-Study/blob/main/database/%EC%9D%B8%EB%8D%B1%EC%8A%A4.md
CS-Study/database/인덱스.md at main · jmxx219/CS-Study
Computer Science && Tech Interview . Contribute to jmxx219/CS-Study development by creating an account on GitHub.
github.com
tech-interview-for-developer/Computer Science/Database/[DB] Index.md at master · gyoogle/tech-interview-for-developer
👶🏻 신입 개발자 전공 지식 & 기술 면접 백과사전 📖. Contribute to gyoogle/tech-interview-for-developer development by creating an account on GitHub.
github.com
https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/main/Database#index
Interview_Question_for_Beginner/Database at main · JaeYeopHan/Interview_Question_for_Beginner
:boy: :girl: Technical-Interview guidelines written for those who started studying programming. I wish you all the best. :space_invader: - JaeYeopHan/Interview_Question_for_Beginner
github.com
Ready-For-Tech-Interview/Database/인덱스(INDEX).md at master · WooVictory/Ready-For-Tech-Interview
💻 신입 개발자로서 지식을 쌓기 위해 공부하는 공간 👨💻. Contribute to WooVictory/Ready-For-Tech-Interview development by creating an account on GitHub.
github.com
'데이터베이스' 카테고리의 다른 글
| [DB] DB Connection Pool (0) | 2025.04.21 |
|---|---|
| [DB] 데이터베이스 락(Locking) & 동시성 제어 (0) | 2025.04.07 |
| [DB] SQL Injection (0) | 2025.03.13 |
| [DB] 트랜잭션 격리 수준 (Isolation Level) (2) | 2025.02.20 |
| [DB] 트랜잭션 (Transaction) (0) | 2025.02.10 |

